Micro review from November
I have tried to put some order into all the links I gathered over the last weeks (including about ten days on vacation with near to zero activity alongside).
I came across Mathematics for Machine Learning again. I already has an older version in my library of PDFs, but now I just downloaded the latest version available for free, and I decided to take a closer look over the next few weeks. Another interesting book is High-Dimensional Probability: An Introduction with Applications in Data Science, but I’m afraid I might be a little short on the time I can devote to all these readings.
While I note that many soft utilities for the command line are written in rust, Go is definitely a serious candidate for web programming, as demonstrated by Hugo or Syncthing, for instance. Lately, I heard about GoAccess for site analytics and it looks really great, even if I already have a small utility (Matomo) to monitor the activity on this site that is good enough for my purpose (I just check the overall traffic once in a while to verify that everything works as expected, i.e. my website is not broken).
How many one-liners cheat sheets are there on Github? Here are two that I find very handy for bioinformatics tasks: Bioinformatics one-liners, by Stephen Turner, and another one, by Ming Tang.
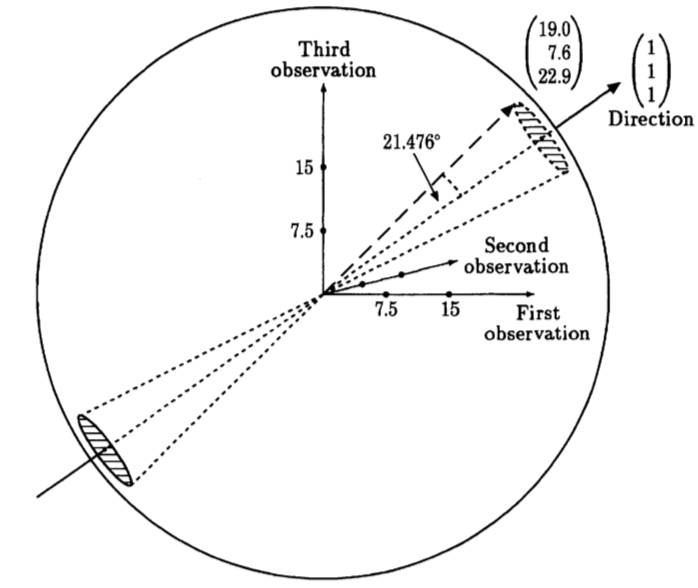
A new angle on the t-test (Wood and Saville, The Statistician, 2002) is a nice paper that I came across, thanks to Giuseppe on Twitter. It illustrates a geometric approach to computing the t statistic (in this case, $t = \sqrt{2}\text{cot}(\theta)$, where $\theta$ denotes the angle between the data vector and a unit vector, and is used to quantify the degree of extremality of the data under the null) and its associated p-value (in this case, the probability under the null that a data vector of a fixed length lies in the double cone) using a paired t-test for 3 samples. This is a short paper, but it provides a very interesting take on the classical t-test.
Cascading cache invalidation, by Philip Walton, deals with caching and, specifically, how to get the benefits of immutable assets and long term caching without cascading cache invalidations. I’m not involved in that sort of business, and I know it is an hard one, but if you’re interested in caching best practice, this article is probably the most recent one that I’ve heard about.
What Every Programmer Should Know About Floating-Point Arithmetic is probably the best way to start with FP arithmetic, if you do not want to dig into the larger PDF version by David Goldberg (HTMLized here). Regarding error propagation, the take away message is probably that multiplication and division are “safe” operations, while addition and subtraction are dangerous, because when numbers of different magnitudes are involved, digits of the smaller-magnitude number are lost. You’ll probably learn more by following John D Cook blog posts, though.
During the last months, I have played with the Rosalind project, both to practice a bit of Python and to better understand some specific aspects of bioinformatics. Now I learned that Philip Compeau has a nice (free) course on bioinformatics algorithms.
There has been some alarming movement on Stack Overflow: moderators resigning, policy updates and a vibrant series of exchange on various meta sites. I am no longer active on any SE sites, but I keep reading some threads on SO meta and several posts on Cross Validated. Here is one of the latest blog posts I have been reading lately: Has StackOverflow Become An Antipattern?
The gamification of StackOverflow is out of control. Votes are no longer related to accuracy and usefulness. Reputation has become the object in-and-of-itself! And when it comes to rep, the rich get richer, the poor get poorer, and it becomes quickly apparent to newcomers that StackOverflow is a losing game for them.